Varför normer?
Att tolka testresultat kräver sammanhang. En normativ databas är ett urval som är representativt för den population som är relevant för jämförelse. Normer fungerar som riktmärken och predicerar testresultat baserat på demografisk data. De används för att jämföra patientens faktiska testresultat med det predicerade resultatet och variansen som finns i den normativa databasen. För Mindmores normer ger denna jämförelse information om din patients prestation i förhållande till en frisk, svensktalande befolkning med liknande demografi. I huvudsak säkerställer normer en nyanserad förståelse av en individs testprestation, vilket underlättar korrekta och individuella tolkningar.
Databasen
Mindmore har en omfattande normativ databas, inklusive 1297 individer i åldrarna 18 till 93 (medelvärde = 48,8, SD = 17,9, tabell 1). Urvalet är välbalanserat över könen, med 782 kvinnor och 515 män. Även om vår datauppsättning är partisk mot högre utbildningsnivåer (medelvärde = 15,4 år, SD = 2,85), innehåller den ett spann från 7 till 26 års uppnådd utbildning. Databasen anses vara representativ för den svensk talande svenska befolkningen (Statistiska centralbyrån). Se även Kvaliteten på Mindmore-normerna per demografisk kategori och Mindmore-normerna per kognitivt test.
Tabell 1.
Mindmores normative databas
|
|
|
|
Ålder |
|
Utbildning |
|
Kön |
|
Inmatningsenhet |
|||||
|
Åldrar |
n |
|
medel |
SD |
|
medel |
SD |
|
Kvinnlig |
Manlig |
|
P-skärm |
Mus |
P-platta |
|
<20 |
16 |
19.1 |
0.50 |
12.0 |
0.73 |
11 |
5 |
11 |
1 |
4 |
||||
|
20 - 29 |
239 |
25.0 |
2.75 |
14.7 |
2.09 |
140 |
99 |
114 |
53 |
72 |
||||
|
30 - 39 |
223 |
34.4 |
2.91 |
16.4 |
2.87 |
108 |
115 |
110 |
62 |
51 |
||||
|
40 - 49 |
184 |
45.0 |
2.96 |
16.1 |
2.88 |
111 |
73 |
95 |
51 |
38 |
||||
|
50 - 59 |
227 |
55.0 |
2.82 |
15.2 |
2.87 |
145 |
82 |
129 |
64 |
34 |
||||
|
60 - 69 |
213 |
65.1 |
2.86 |
15.1 |
2.66 |
135 |
78 |
115 |
72 |
26 |
||||
|
70 - 79 |
165 |
74.0 |
2.68 |
15.5 |
3.29 |
108 |
57 |
110 |
44 |
11 |
||||
|
80+ |
30 |
84.3 |
4.00 |
13.8 |
3.15 |
24 |
6 |
25 |
4 |
1 |
||||
|
Total |
1297 |
|
48.8 |
17.9 |
|
15.4 |
2.85 |
|
782 |
515 |
|
709 |
351 |
237 |
|
Note P-skärm = Pekskärm, P-platta = Pekplatta |
||||||||||||||
Normativ prediktion av testprestation
Mindmore använder regressionsbaserade normativa modeller för att förutsäga testprestation för varje enskild patient (Van den Hurk et al., 2022). Normativa modeller använder hela datauppsättningen för att förutsäga resultat för alla kombinationer av ålder, kön, år av uppnådd utbildning och inmatningsenhet (pekskärm, mus eller pekplatta). Genom att använda hela urvalet förbättrar vi noggrannheten i prediktionen jämfört med stratifierade normer (Knight et al., 2006; Oosterhuis et al., 2016). Ålder och antal år uppnådd utbildning behandlas som kontinuerliga variabler, vilket innebär att varje ytterligare år påverkar prediktionen. Dessutom gör detta tillvägagångssätt det möjligt för att undersöka ytterligare prediktorer, såsom inmatningsenhet, och komplicerade effekter, såsom interaktionen mellan ålder och utbildning.
En patients testresultat jämförs med det testresultat som prediceras utifrån normerna. Denna skillnad jämförs i sin tur med den naturliga variansen. Måttet för denna varians kommer också från den normativa databasen, där de faktiska testresultaten skiljer sig från de förutspådda testresultaten i modellen de bygger, residualvariansen. Om variansen är lika i hela modellen används en enda siffra för detta testresultats naturligt förekommande varians. Om variansen skiljer sig åt beroende på det förutsagda resultatet (t.ex. mindre varians med högre predikterade testresultat), delas provresidualerna upp i tre grupper och tre olika siffror används för den naturligt förekommande variansen, beroende på patientens förutsagda testresultat.
Ett exempel
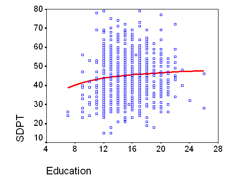
Modellen för SDPT (Symbol Digit Processing Test) bygger på 791 datapunkter i åldrarna 18 till 91 (figur 1). Dessa testresultat visade en signifikant påverkan av en icke-linjär effekt av ålder (accelererad nedgång i prestanda med ökande ålder), en icke-linjär effekt av utbildning (en ökning av prestanda ses främst för de första åren av uppnådd utbildning), och bättre prestanda för pekskärm jämfört med mus (cirka 1,6 fler korrekta svar), och sämre prestanda på pekplatta jämfört med mus (cirka 4,4 mindre korrekta svar). Residualvarianseniansen för modellen är ca 6,7 korrekta svar i hela modellen, en siffra för den naturligt förekommande variansen används.
Figur 1. SDPT-testprestanda, påverkad av ålder, utbildning och inmatningsenhet.
.png?width=227&height=182&name=unnamed%20(2).png)
.png?width=226&height=181&name=unnamed%20(3).png)
Note: SDPT = Symbol Digit Processing Test, T-pad = pekplatta, T-screen = pekskärm, mouse = mus.
”All models are wrong, but some are useful.”
Verkligheten för kognitiv prestation är extremt komplex. Kognitiva tester används för att mäta kognitiv funktion, där varje test är specialiserat på att mäta en eller ett fåtal kognitiva funktioner. Patienternas prestationer på de kognitiva testerna approximerar deras prestationer i dessa kognitiva funktioner. Vi vet att ett antal variabler såsom ålder och antal år utbildning har en tillförlitlig inverkan på kognitiva testresultat. Vi kontrollerar för denna påverkan genom att inkludera dem som prediktorer i de normativa modellerna. Det finns dock mycket mer som påverkar testprestation, till exempel att vara utvilad eller stressad, som inte enkelt kan inkluderas i modellerna. Denna typ av varians är vad vi kallar den naturliga variansen som förekommer för varje kognitivt test och som approximeras av modellresidualerna.
Vi närmar oss den naturligt förekommande variansen som normalfördelad runt den förutsagda prestandan (Figur 2). Detta innebär att även i den friska populationen förväntar vi oss att cirka 5 % av individerna ska prestera mer än 2 standardavvikelser från den förutspådda prestationen (en z-poäng på under -2,0 eller över +2,0); och nästan en tredjedel för att prestera mer än en standardavvikelse från den förutspådda prestandan (en z-poäng på under -1,0 eller över +1,0). Dessutom är verkligheten med naturligt förekommande varians på testprestanda och kognitiv funktion mycket mer komplex än en sådan normalitetskurva. Såvitt vi vet är detta dock den mest användbara approximationen som för närvarande finns tillgänglig för att uppskatta hur en patients prestation på de kognitiva testerna relaterar till vad som kan förväntas av dem som en del av den friska populationen.
Figur 2. Naturligt förekommande varians i testprestanda, modellerad som normalt fördelad kring den testprestanda som förutsägs av normerna.
.png?width=444&height=253&name=unnamed%20(1).png)
Slutsatser
Den robusta metodiken som används av Mindmore, förankrad i expansiva normativa data, ger en nyanserad förståelse för individuella testprestationer. Våra modeller utforskar både linjära och icke-linjära effekter, interaktioner och enkla effekter, och fångar subtila nyanser i testprestanda över demografi.
Referenser
Crawford, J. R., & Garthwaite, P. H. (2006). Comparing patients’ predicted test scores from a regression equation with their obtained scores: A significance test and point estimate of abnormality with accompanying confidence limits. Neuropsychology, 20(3), 259–271. https://doi.org/10.1037/0894-4105.20.3.259
Knight, R. G., McMahon, J., Green, T. J., & Skeaff, C. M. (2006). Regression equations for predicting scores of persons over 65 on the Rey Auditory Verbal Learning Test, the mini-mental state examination, the trail making test and semantic fluency measures. British Journal of Clinical Psychology, 45(3), 393–402. https://doi.org/10.1348/014466505X68032
Oosterhuis, H. E. M., van der Ark, L. A., & Sijtsma, K. (2016). Sample Size Requirements for Traditional and Regression-Based Norms. Assessment, 23(2), 191–202. https://doi.org/10.1177/1073191115580638
Statistiska centralbyrån. (n.d.). SCB Statistikdatabasen. Statistikdatabasen. https://www.statistikdatabasen.scb.se/